Here i am going to explain – Where to check Hana Errors & Logs & location of SAP Hana Trace file location :
Go to Path -> /usr/sap/<SID>/HDB00/<hostname>/trace
Here you’ll get trace files for all SAP Hana Process/Services:

Here i am going to explain – Where to check Hana Errors & Logs & location of SAP Hana Trace file location :
Go to Path -> /usr/sap/<SID>/HDB00/<hostname>/trace
Here you’ll get trace files for all SAP Hana Process/Services:
Here i am going to explain -How to Check SAP Hana Services | HANA is up and running from SAP HANA Studio ?
Open SAP HANA Studio –> Select “System” –> Double click on system–> Select Landscape
Here you’ll find status of all Hana Services :If SAP HANA is up and running fine then for all services ,status should be green.

<hostname>:/usr/sap/<SID>/HDB00> /usr/sap/hostctrl/exe/sapcontrol -nr 00 -function GetProcessList
28.10.2017 18:45:27
GetProcessList
OK
name, description, dispstatus, textstatus, starttime, elapsedtime, pid
hdbdaemon, HDB Daemon, GREEN, Running, 2017 10 12 14:14:10, 388:31:17, 9240
hdbcompileserver, HDB Compileserver, GREEN, Running, 2017 10 12 14:14:14, 388:31:13, 9384
hdbindexserver, HDB Indexserver, GREEN, Running, 2017 10 12 14:14:16, 388:31:11, 9418
hdbnameserver, HDB Nameserver, GREEN, Running, 2017 10 12 14:14:11, 388:31:16, 9257
hdbpreprocessor, HDB Preprocessor, GREEN, Running, 2017 10 12 14:14:14, 388:31:13, 9386
hdbwebdispatcher, HDB Web Dispatcher, GREEN, Running, 2017 10 12 14:14:45, 388:30:42, 9752
hdbxsengine, HDB XSEngine, GREEN, Running, 2017 10 12 14:14:16, 388:31:11, 9420
In this guide,I explain different Hana Monitoring Checks that we need to perform in daily health check of SAP Hana System.
SAP Database T Codes
=================
DBCO – database Connection Maintenance
DBACOCKPIT – Start DBA Cockpit
DB11 – Create database Connection
SAP Sybase ASE
================
ASE is short for “Adaptive Server Enterprise”, the relational database management software manufactured and sold by Sybase, Inc. ASE is a versatile, enterprise-class RDBMS which is especially good at handling OLTP workloads. ASE is used intensively in the financial world (banks, stock exchanges, insurance companies), in E-commerce, as well as in virtually every other area.
The most recent ASE release is ASE version 15.7 (released September 2011); the previous release is version 15.5.
ASE 15.7 is also known as “the SAP release” since this is the ASE version that SAP is using to support the Business Suite ERP package on top of Sybase ASE.
ASE runs on the main flavours of Unix, on Linux, and on Windows.
========================================================================
Sybase Architecture
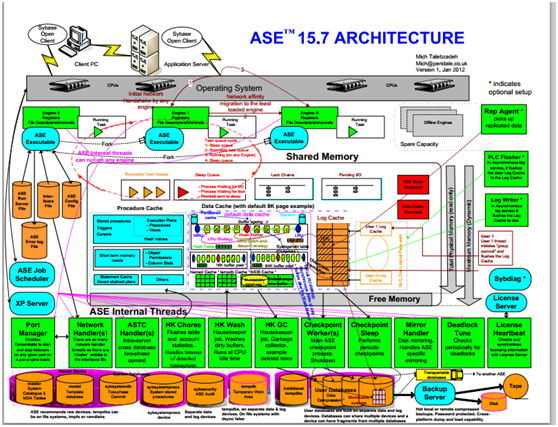
Installation Directory Contents and Layout
SAP ASE includes server components that are installed into specific directories
| Product | Description |
| SAP ASE | >Installed into the ASE-16_0 director >SAP ASE – the database server. >Backup Server – an application based on SAP® Open Server™ that manages all database backup (dump) and restore (load) operations. > XP Server – an Open Server application that manages and executes extended stored procedures (ESPs) from within SAP ASE. >Job Scheduler – provides a job scheduler for SAP ASE. Job Scheduler components are located in ASE-16_0\jobscheduler\. |
| Connectivity | Installed into the OCS-16_0 directory: >Open Client™ (Client Library, dblib) >ESQL/C >ESQL/COBOL >XA >Installed into the DataAccess and DataAccess64 directories: >ODBC (Windows, Solaris SPARC, Solaris x64, Linux Power, HP-UX Itanium, IBM AIX) – a driver used to connect to SAP ASE from ODBC-based applications. >ADO.NET (Windows only) – a provider used to connect to SAP ASE from .NET based applications. |
| Shared Directory | The Shared directory contains components and libraries that are shared by several other components. In earlier versions, this directory was named Shared-1_0. > Java Runtime Environment (JRE) – is a runtime Java virtual machine used to execute Java-based programs, such as SAP Control Center. SAP ASE includes the JRE. In typical installations, by default, the JRE is fully installed. In custom installations, if you select a component for installation that requires the JRE, the JRE is also automatically selected. It is located in the Shared\SAPJRE-7_0 * directory. |
| SAP Control Center | SAP Control Center logs and utilities – files related to the Web-based tool for monitoring the status and availability of SAP ASE servers. They are installed into the %SYBASE%\SCC-3_3 directory.Note: The SAP ASE typical installation option installs only the SCC Remote Command and Control (RCC) agent. To use a GUI-based connection to the SCC server using a Web browser, you must use the custom installation option to install the SCC Management User Interface for SAP ASE. |
| Language Modules | Installed into the locales directory. Provides system messages and date/time formats. |
| Character Sets | Installed into the charsets directory. Provides character sets that are available for use with SAP ASE. |
| Collation Sequences | Installed into the collate directory. Provides the collation sequences that are available for use with SAP ASE. |
| Sybase Software Asset Management (SySAM) | Installed into the SYSAM-2_0 directory. Provides asset management of SAP ASE servers and optional features. |
| Web Services | Installed into the WS-16_0 directory. An optional product that provides access to SAP ASE using HTTP/SOAP and WSDL. |
| Interactive SQL | Interactive SQL is a GUI tool that allows you to execute SQL statements, build scripts, and display data from SAP ASE. It is installed into theDBISQL-16_0 directory. |
| jutils-3_0Utilities | A collection of SAP ASE utility programs including ribo, a tool to trace TDS traffic between a client program and SAP ASE. |
| SAP®jConnect™ for JDBC | Installed into the jConnect-16_0 directory. Provides a Java Database Connectivity (JDBC) driver for SAP ASE. |
| OData Server | Installed into the ODATA-16_0 directory, OData (Open Data Protocol) enables data services over RESTful HTTP, allowing you to perform operations through URIs (Universal Resource Identifiers) to access and modify information. |
Sybase ASE Database structure in detail
When installing SAP with Sybase ASE 15.7 we will get the following databases by default.
1) Master
2) Model
3) Tempdb
4) SID(User Specific Database)
5) Sybtempdb
6) Saptools
7) Sybmgmtdb
8) Sybsystemprocs
Each database must have at least one device nothing but datafile. Devise is nothing but a physical file or a device on Operating System Level.
Master, model and tempdb are by default stored in “master.dat” device.
The file path to “master.dat” file is à /sybase//sybsystem.
And the user specific database is created with datafile(data_1.dat) and logfile(log_1.dat) if you want you can increase the datafiles number as well as logfiles number.
Path to these files are à “/sybase//sapdata_1…” and
“/sybase//saplog_1…”
If you want you can increase the no.of datafiles or increase the size of the data files.
And the other db device files are à
datasaptools.dat
logsaptools.dat à these two stored in (“/sybase//sapdiag/”)
sybmgmtdb.dat
sybsysdb.dat
sysprocs.datà These three stored in (“/sybase//sybsystem” along with “master.dat”)
tempdadev.datà stored in (“/sybase//sybtemp”)
Master Database:-
Master database stores information on all user databases and their associated devices.
And it also stores information about database users, objects.
Sysdatabases(all databases on ASE)
Sysdevices(mounted devices)
Sysusages(storage space allocated to each DB),etc are important tables in master Database.
How to extend a device?
To extend a device we need to execute the following command
disk resize
name = logical_name_of_device
size = “value”
example:-
disk resize
name = data_1
size = “10G”
Then alter disk
Alter database <databasename> log on < logical_name_of_device> =”value”
eg:-Alter database SID log on data_1 =”10G”
The above command is used to increase the datafile data_1 to 10GB.
After increase the datafile (data_1) to take the changes effect to the database.we need to execute the following command.
Alter database data on data_1 10G.
To confirm the changes check with sp_helpdb
Database Backup & Restore
Dump database to “file Path”
Ex:-dump database ASB to “D:\backup\backup_SID.dmp”
dump database master to “D:\backup\backup_master.dmp”
The datafiles and logfiles of the database you specified are backed up with the dump command.
The backup log file are stored in file SID_BS.log in the folder “/sybase//ASE_0/install/_BS.log”
In the backup fail situations we can check this file for details.
For restore we can use the command,
Restore database from “backup_file”
Restore on same SID/diff SID :-
To Backup the database use the load command at the isql prompt
isql -Usapsa -S<SID> -X
then run the following command at the sql prompt
1>dump database <SID> to “d:\backup\backupxxx.dmp” with compression = “101”
2>go
=============
Following command we are tried for backup on tape drive.
1> use master
2> go
1>sp_config_dump @config_name=’SIDDB’,
2> @stripe_dir = ‘-i /dev/rmt0’ ,
3> @compression = ‘101’ ,
4> @verify = ‘header’
5> go
=============
To Restore the database use the load command at the isql prompt
1>load database from ‘d:\backup\xxxxx.dmp’
2>go
1>online database <DBSID>
2>go
SAP sybase iSql Command Prompt
========================================================================
Sp_helpdb
Sp_helpdevice
Sp_adddumpdevice
You can now start typing T-SQL commands and use the keyword “go” as a terminator.
isql -Usa -P -SSERVER
1> select @@version
2> go
We can log out by telling isql to disconnect using the exit command.
1> exit
We will make our new login default to an example database instead to avoid creating objects in the master database by mistake. So, we first set a password for sa by calling the stored procedure sp_passwordwith old and new passwords as parameters:
1> exec sp_password NULL, “Secr3t”
2> go
Password correctly set.
(return status = 0)
Now sa has a new password, changed from the old null default. We add a new login with sp_addlogin:
1> exec sp_addlogin “sybtest”, “SomePass”
2> go
Password correctly set.
Account unlocked.
New login created.
(return status = 0)
The isql command can also be used non-interactively to apply scripts of T-SQL to the server. One such script that is shipped with the server is installpubs2, located in the scripts directory. This is a very simple example database for a bookshop or a publishing house holding data about books, authors, publishers and so on. It is used in Sybase manuals and training courses and also in some SQL books. Microsoft SQL Server contains a similar database in addition to the Northwind example database they have added. In order to create the database, use the -i parameter to read the script in. Have a look at the file first so you understand the basics of what it is doing; it will create a database named pubs2 and several tables populated with data. It is time to execute the script. We’ll do this as sa who will also become the owner (dbo – database owner ) of the database. We redirect the output to a file we call errors.out. The -e parameter tells isql to also echo the T-SQL commands to the same file, giving more output but making it easier to match any errors to the commands causing them.
bash$ cd $SYBASE/$SYBASE_ASE/scripts
bash$ isql -Usa -PSecr3t -SSYBASE -iinstallpubs2 -e -oerrors.out
In order to allow our new login full privileges to this sample database we change ownership of the database to the new login. Here’s how we give the database away with sp_changedbowner:
isql -Usa -PSecr3t -SSYBASE
1> use pubs2
2> go
1> exec sp_changedbownersybtest
2> go
DBCC execution completed. If DBCC printed error messages, contact a user with
System Administrator (SA) role.
Database owner changed.
(return status = 0)
We can now log in interactively as our new user and check what has been installed.
1> exit
bash$ isql -Usybtest -PSomePass -SSYBASE
1> use pubs2
2> go
1>sp_help
2> go
[Lots of output deleted – the command displays all objects in the current database]
(Note that we don’t actually have to use “exec” to execute a stored procedure, the server will assume any non-keyword is a procedure.)
1> quit
One last command as the sa login in order to make life more convenient when we continue to use our new login – we make the new pubs2 database the default database.
1> exit
bash$ isql -Usa -PSecr3t -SSYBASE
1>sp_modifyloginsybtest, “defdb”, “pubs2”
2> go
Default database changed.
(return status = 0)
________________________________________
4.4. Stopping the Server
In order to stop the server in a controlled fashion, log in as sa and issue the shutdown command.
bash$ isql -Usa -PSecr3t -SSYBASE
1> shutdown
2> go
Server SHUTDOWN by request.
The SQL Server is terminating this process.
CT-LIBRARY error:
ct_results(): network packet layer: internal net library error: Net-Library operation terminated due to disconnect
You will immediately be disconnected and a message is printed by isql to warn you of this fact. You can check the error log for a message about the server being shutdown and you can verify that the process is no longer running with showserver.
4.5. Maintenance
One of the most important aspects of being a database administrator may be the backup. The I/O load of a relational database means little rest for the hard drives and once a drive fails the database is in need of serious disaster recovery. Even a mistyped command may result in the need to revert to a previous backup generation. For this purpose, a separate server application called the Backup Server is used. It is by default named the same as your server with an extension of BCK. Start it with startserver -f RUN_SYBASE_BCK. Certain commands typed into the isqlpropmt will be forwarded from thedataserver process to the backupserver process, which will then proceed with the actual backup (in Sybase terminology, this is a database dump) while processing in the database continues unaffected. You should schedule database dumps (usually via cron) to run at low activity hours. A typical full database bacup is simply done like this:
isql -Usa -PSecr3t -SSYBASE
1> dump database pubs2 to “/mnt/backup/pubs2.bkp”
2> go
Backup Server session id is: 8. Use this value when executing the
‘sp_volchanged’ system stored procedure after fulfilling any volume change
request from the Backup Server.
Backup Server: 4.41.1.1: Creating new disk file /mnt/backup/pubs2.bkp.
Backup Server: 6.28.1.1: Dumpfile name ‘pubs2011710275E ‘ section number 1
mounted on disk file ‘/mnt/backup/pubs2.bkp’
You can restore this back into your database using the load database command.
As time passes while users are doing modifications in the database, adding, deleting or changing data, all operations are being written to the transaction log. This keeps track of changes so they can be undone by an implicit or explicit rollback, or for the undo/redo phases of revocery at startup. This transaction log should normally be placed on a device of its own for several reasons, but a small test database can be created on a single mixed log and data device.
Apart from the performance benefits of spreading I/O, one reason for keeping the log and data separate is for recovery purposes. You can at regular intervals, depending upon your recovery needs, dump this log of changes to the database. Together with the full database dump, this transaction log dump now constitute an incremental backup. Should a restore become necessary, you can load the database dump, then load all subsequent transaction log dumps. There is even an “until_time” option to the load command enabling you to specify the exact time you want to restore until, abandoning any mistakes done after that time. Dumping the log is done with a similar syntax:
isql -Usa -PSecr3t -SSYBASE
1> dump transaction database to “/mnt/backup/dbtrandump2003_08_27_T23_32.bkp”
2> go
Note that we could not do this with pubs2 as it was not created with a separate log fragment.
Unless you keep dumping the transaction log, it will just keep growing until it fills up it’s space and starts reporting error 1105. Users will be suspended and appear to be hanging while the situation remains unresolved. Dump the transaction log to file or tape, or simply truncate it if you don’t use incremental backups.
isql -Usa -PSecr3t -SSYBASE
1> dump transaction pubs2 with truncate_only
2> go
1>
Other maintenance commands you should read up on are
• DBCC, the DataBase Consistency Checker which will verify that the physical integrity of the data structures on the ASE devices are OK.
• update statistics, which will make sure that ASE has a correct view of how your data is distributed in your tables, enabling it to make the best decisions of how to retrieve the data in the shortest possible time.
5. ASE Architecture: Observing the Server
5.1. Processes
A simple ps will show you the dataserver processes (by default you only have one), Sybase has provided a utility named showserver that will just show you the Sybase-related processes that are active. Thesp_sysmon stored procedure will monitor ASE for a given time interval, then dump out several pages of global performance data. The Engine section shows how active the server really is, regardless of the CPU usage shown on OS level.
5.2. Physical Storage
The ASE server does I/O to the raw devices or files, these are represented internally as virtual devices. A database can reside on one or spread out on many of these virtual devices, and a virtual device can hold many databases if you want. You should locate the OS-level device files on fast disks and make sure they are not removed or messed with by other applications or sysadmins on a cleanup crusade. The path to the virtual devices are stored in the master..sysdevices table, you can list these with the sp_helpdevice stored procedure.
5.3. Network
The server listens for incoming connections on one or several TCP ports. You identify the server by the logical Sybase server name when you connect. This logical name is listed in the interfaces file, used by both ASE server and clients such as isql. When the ASE server is started, it finds it’s name in the RUN_SERVER file, looks this up in the interfaces file, finds the master entry and starts a listener on the IP / port found there. When you start isql it also looks for the logical server name in the interfaces file, but looks for the query line instead. Normally this is the same IP and port, but it gives you the option of starting the server on several different IPs and ports and configure clients in different parts of the network to utilize different pathways to the server. JDBC does not use the interfaces file, but instead lets you use the IP and port as part of the URL.
You can observe the open port and established connections with netstat or lsof -i. It is also possible to trace the communication using tcpdump or Ethereal, these utilities have support for the Tabular Data Stream (TDS) protocol used in Sybase client-server connections.
Once a client has connected it will be visible inside ASE as a task, an internal process. These are not seen as separate OS processes, but can be listed with the sp_who stored procedure.
5.4. Memory
You can configure how much memory you want ASE to use down to a certain needed minimum and up to whatever your OS and your ASE version combination will allow you. Except for doing careful analysis and clever design and SQL writing, using more of the available memory is what makes databases speed up without changing hardware. By default, most of the memory you allow allocated to ASE is used for caching data to avoid disk I/O as much as possible. Another area of memory is used to cache stored procedures in a compiled form, enabling these to be readily re-used without having to read from disk as frequently. Smaller parts are reserved for various administrative memory structures needed by the server for keeping track of each user connection, each database and so on.
On OS level you can see this normally contiguous memory chunk with ipcs -m. Inside ASE you can usesp_configure to read and modify configuration parameters such as total memory. There are several ways of determining the efficiency of memory usage, this art is explained in the Performance and Tuning Guide.
You can use sp_errorlog to cause ASE to start logging to a new file, then archive or delete the original file.
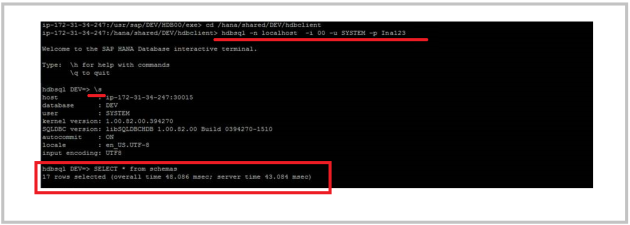
Requirement: You want to access SQL prompt using HDBSQL at OS level.
SAP HANA appliance software is a flexible, multipurpose, data-source agnostic in-memory appliance that combines SAP software components optimized on hardware provided and delivered by SAP’s leading hardware partners.
The SAP HANA appliance enables organizations to analyze business operations – based on large volumes of transactional and analytical data as it develops – and to instantly explore and analyze the data from virtually any data source in real time. Data is captured in memory as business happens, and flexible views expose analytic information rapidly. External data can be added to analytic models to expand analysis across the entire organization.
SAP and IBM announce impressive performance test results of SAP HANA
SAP In-Memory Appliance software (SAP HANA) easily handles 10,000 queries per hour against 1.3 terabytes of data and returns results within seconds, according to the first official SAP HANA performance test. SAP and IBM announced the test results today; they have been working on a joint project to deliver real-time analytics.
SAP HANA is based on in-memory technology which enables data to be analyzed in a matter of seconds. Unlike with traditional databases, in-memory computing eliminates the need for IT departments to extract, aggregate, or process data – information is stored directly in the in-memory database. From there, it can be accessed immediately, which enables real-time data analysis.
The test was independently audited and verified by WinterCorp. SAP and IBM designed the test to reflect the requirements of today’s business and based the queries on the typical workload of SAP ERP users. For hardware, they used an IBM x3850 X5 server. The IBM x3850 X5 server contains 32 cores, 0.5 terabytes of memory, and a RAID 5 disk system. With SAP HANA software, the server can handle up to 1.3 terabytes of data, as SAP HANA compresses data and stores it in columns.
IBM says DB2 is ready for HANA. (We will wait for Oracle 🙂 )
SAP and IBM’s partnership to support SAP HANA is part of a long history of collaboration, making SAP systems run more efficiently on IBM databases and hardware. Good news for customers with ERP systems that run on DB2.
At the moment, SAP HANA is still in the ramp-up phase. There are around 50 customers using the software in the co-innovation program. SAP HANA is the in-memory foundation on which a new family of applications will be built.
SAP HANA Now Generally Available to Customers Worldwide
Customer Pipeline is One of Fastest Growing in SAP’s History
WALLDORF, Germany – June 21, 2011 – SAP AG (NYSE: SAP) today announced the general availability of SAP HANA™ appliance software to customers globally, heralding a new generation of analytics, business applications and IT simplification with SAP in-memory computing technology. The company also announced that Mitsui, one of the world’s most comprehensive trading companies, has selected SAP HANA. Mitsui joins a growing list of customers around the world that are already seeing the technology’s value, including Charité – Universitätsmedizin Berlin, The Charmer Sunbelt Group, Hilti and Medtronic. (See customer testimonial videos on SAP HANA.)
First conceived last spring, SAP HANA was delivered to select customers in November 2010 and today is made generally available as promised. SAP HANA has one of the fastest growing sales pipelines for new products in SAP’s history.
SAP HANA introduces a new paradigm of real real-time computing, allowing companies to re-think their existing business challenges and tackle entirely new ones. With SAP HANA, customers can approach their business needs in profoundly different ways by using breakthrough analytics, unprecedented new applications and renewed existing SAP solutions.
For example, one customer is using SAP HANA to run real-time simulations to understand profitability and improve margins per project using granular revenue and cost data. Another customer that provides IT services for transportation companies is using SAP HANA to search through 360 million traffic records in a little over one second, allowing taxi companies to direct and dispatch cabs more efficiently and in real time. In addition, many customers are using SAP HANA to pull both SAP and non-SAP data. For example, a Fortune 100 company is using SAP HANA primarily for non-SAP application data sources from within the company and those coming from manufacturing partners.
As part of SAP’s commitment to innovation without disruption, SAP HANA is designed to bring these benefits to companies without interrupting their existing IT systems. Moreover, SAP HANA can help customers streamline those systems by eliminating layers of the traditional stack.
“General availability is a major milestone for SAP HANA, but this is just the beginning,” said Dr. Vishal Sikka, executive board member, Technology and Innovation, SAP AG. “SAP HANA brings a fundamental transformation to the way companies run their businesses and is at the heart of innovation across our entire product and technology portfolio at SAP. As we showed at SAPPHIRE NOW a few weeks ago, SAP HANA provides significant business value to customers, and I look forward to the next milestones with SAP HANA, building breakthrough new applications and building out the SAP HANA application cloud to deliver them.”
The following services can exist in SAP HANA environments (‘xx’ is a placeholder for the instance ID):
| Service | Port (single instance) | Port (multitenant) | Details |
| daemon | 3xx00 | 3xx00 | Monitoring and controlling of SAP HANA instance state |
| nameserver | 3xx01 | 3xx01 | Administrative tasks like:
System database of multitenant systems (SAP Note 2101244):
|
| preprocessor | 3xx02 | 3xx02 | Text processing tasks, e.g. for text search |
| indexserver | 3xx03 | 3xx40 and higher | Main SAP HANA service:
|
| scriptserver | 3xx04 | 3xx40 and higher | Execution of C++ AFL libraries |
| statisticsserver | 3xx05 | n/a | The standalone statistics server is embedded in the indexserver with SAP HANA 1.00.93 and higher (SAP Note 2147247), so it no longer exists as a dedicated service. |
| webdispatcher | 3xx06 | 3xx06 | Processing of http requests |
| xsengine | 3xx07 | 3xx40 and higher | Native SAP HANA application server (XS Classic), will be over time replaced with XS Advanced |
| hdbrss | 3xx09 | 3xx09 | Remote support daemon (SAP Note 1058533)Not a real service |
| compileserver | 3xx10 | 3xx10 | Responsible for compilation of procedures |
| dpserver | 3xx11 | 3xx40 and higher | Smart data integration support (SAP Note 2400022) |
| esserver | 3xx12 | 4xx12 | Dynamic tiering support |
| streamingserver | 3xx16 3xx26 |
3xx16 3xx26 |
Smart data streaming support |
| etsserver | 3xx21 – 3xx24 | 3xx21 – 3xx24 | Accelerator for SAP Adaptive Server Enterprise (ASE) |
| diserver | 3xx25 | 3xx05 (systemdb) 3xx25 (migrated tenant) 3xx40 and higher (normal tenant) |
Deployment infrastructure (HDI) |
| rdsyncserver | 3xx27 3xx28 |
3xx27 3xx28 |
Remote data synchronization (real-time replication with SAP SQL anywhere) |
| xscontroller | 3xx29 3xx30 3xx33 |
3xx29 3xx30 3xx33 |
XS Advanced (XSA) controller |
| xsuaaserver | 3xx31 3xx32 |
3xx31 3xx32 |
XS Advanced (XSA) core service for controller |
| xsexecagent | dynamic | dynamic | XS Advanced (XSA) execution agent |
| docstore | 3xx60 | 3xx60 | Document store repository access via JSON |
| sapstartsrv | 5xx13 5xx14 |
5xx13 5xx14 |
Start / stop of SAP HANA services and monitoring their state |
Be aware that there can be deviations from the port mappings described above, e.g.:

If you are unable to import a profiles(SAP_ALL) transport into multiple clients on the same system (Say you wanted to import the user master into multiple clients on an ECC system) and it gives you the “Release of export and import systems have to be identical’ error. (as shown below) in STMS when you try to import into a second client
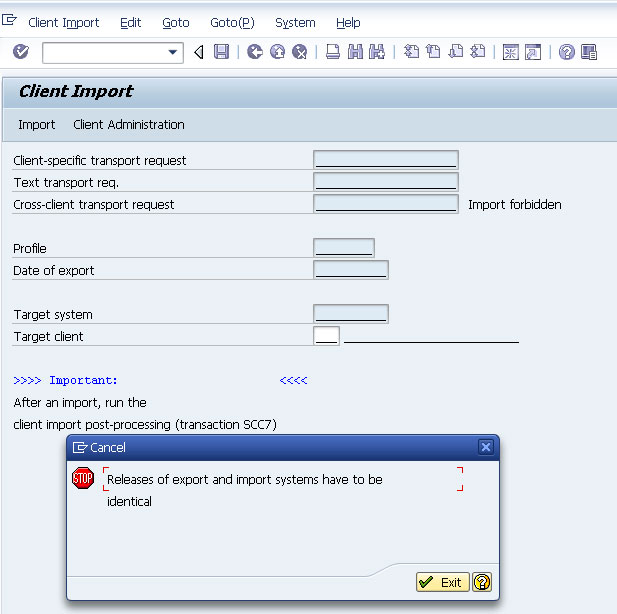
You need to manually force the transport into the system using the TP command. Do the following:
1. Remote into an application server for the appropriate system
2. Launch a command prompt. Navigate to the D:\usr\sap\trans\bin directory
cd D:\usr\sap\trans\bin
3. Now run the following command (replacing the SID. Transport ID and client number as appropriate)
D:\usr\sap\SID\SYS\exe\uc\NTAMD64\tp.exe import TRANSPORTID SID client###U128 pf=D:\usr\sap\trans\bin\TP_DOMAIN_SID.PFL
It will take a few minutes to complete the import.
You know it is imported when the command window goes away. Now you can run SCC7 to complete the post-processing as normal. Repeat on other clients as necessary
